Generative AI has become a widespread fixation, an obsession even, over the past five years or so. Ever since it exploded onto the web, ChatGPT, its LLM siblings and image-generating cousins, have become an inescapable fact of everyday life. Their reach has extended well beyond the online or digital media realms I normally inhabit. Seemingly everyone is using it, evangelizing for it, lying about using it, getting caught using it, or perhaps railing against the very concept.

I can hardly get through a day without seriously considering the implications of AI for virtually any sector of daily life. LLMs like ChatGPT, Copilot, Claude, and Gemini have seemingly become commonplace in a wide array of fields from management consultancy, law and litigation, videogame development, and government. Education, especially higher education, has been particularly implicated. Yet, in each and every one of these cases, the ‘story’ is about the disastrous impact of AI in that specific instance. In the absence of obvious success stories not drawn from the vendor’s marketing department, I find myself seeking answers. How did we, as a society, become primed for such a deeply flawed technology to take over?
One answer lies in the generalised financial house of cards that has been built on top of Silicon Valley. There is little doubt that generative AI, as an industry, is vastly overvalued. Even worse, tremendous speculative investment is tied up in a miniscule number of actual companies, with OpenAI and Nvidia chief among them. There are plenty of accounts of that angle, and I am not best placed to write another.
As a scholar in digital media studies however, I am perhaps better placed to analyse the product that Gen AI creates. I’ve been teaching classes in writing this year, so I’ll largely focus on the verbal output of LLMs, but I think the argument will apply to visual media as well.
The conclusion I’ve come to is that, even though the output of an LLM is “text”, it isn’t “writing” and is certainly not “communication”, because it doesn’t mean anything.

I can’t fully unpack all of this in a blog post, but I am deliberately invoking the concepts of meaning-making, semiotics, reader-response, and various related deconstructive perspectives on meaning and communication more broadly. I am gesturing towards the post-modern preference for the interpretation of the meaning of a text that occurs in the reader, than the meaning construction process that the author may have intended.
I am suggesting, as Bruno Latour finally did, that the Barthes, Lyotards, Baudrillards, and Bruno Latours of the world may have actually gone too far in killing the author; we may have also inadvertently murdered meaning.
Earlier this year, APM published an article by Rachel Sender which analysed a widely-adopted system of teaching children to read. This deep-dive finally provided me with a more concrete manifestation of my steadily growing fears about our general ability to communicate meaning in a general sense. The “three cueing” system of reading, as described by Sender, involves young students learning to use three different “cues” to deduce (guess) the meaning of an unfamiliar word. Those cues include:
- graphical cues (what do the letters tell you about what the word might be?
- syntactic cues (what kind of word could it be, for example, a noun or verb?)
- semantic cues (what word would make sense here based on context?)
So, rather than teaching children a precise, systematic approach to sounding out words one letter at a time (phonics), or through the “whole word” recognition practice, students instead “think of a word that makes sense and ask: Does it look right? Does it sound right? If a word checks out on the basis of those questions, the child is getting it.”
Sender’s article is stridently critical of this scientifically disproven theory. The article is littered with shocking examples, such as a case involving teacher Margaret Goldberg:
She was with a first-grader named Rodney when he came to a page with a picture of a girl licking an ice cream cone and a dog licking a bone.
The text said: “My little dog likes to eat with me.”
But Rodney said: “My dog likes to lick his bone.”
Rodney breezed right through it, unaware that he hadn’t read the sentence on the page.

When I first encountered this example, I was blown away. While a sufficiently enthusiastic critic could surely make a case for interpreting the work here in myriad ways, which could certainly include the fact that the dog seems to be enjoying licking the bone, that isn’t actually reading. We aren’t talking about a creative or personal interpretation of the gestalt of a text. This is a wholesale substitution of a “private reading” in the place of a clear and unambiguous message encoded in plain language.
Young Rodney has, in fact, done something quite similar to what ChatGPT or Claude does: based on an established string of text, he generated a probabilistic, plausible conclusion to the sentence. The sentence does follow grammatical and syntactical rules. It is, superficially at least, relevant to the situation. And it “felt right” to Rodney. But he was wrong about the sentence. He did not grasp the meaning, and therefore he failed to communicate.
In schools where critical analysis is taught, we have continued to tell students not to simply believe what the text “says.” Instead, they should look for subtext, interpret from a different perspective, apply a novel theoretical framework, and come to their own conclusions. We’ve decentered the author, cleaved them from the “authority” of the position, and welcomed a far more diverse range of perspectives to the critical canon. Taken far enough, we eliminate the author entirely, rendering their original intention irrelevant.
But that is, as I suggested above, too far. While we must continue to create and defend inclusive spaces in which to interpret, we should also remember that communication is always a two-part (at minimum) affair. There is someone on the other end of the line, who at least tried to communicate something meaningful. If that is not the case, then it truly does not matter what is on the page, and Rodney can dream up whatever explanation fits his personal perspective at the time.
Furthermore, in a situation where even a large fraction of the population “reads” the way Rodney does, then what the author might have actually tried to say rarely if ever figures into the interpretive process. So, audiences might utterly fail to comprehend an article, but carry on with a personally-constructed version that feels right in their own mind, without a moment’s pause.
As I read Sender’s examples, I continually tripped over the “feels right” judgement call that these children were invited to make. It begged the question: on what basis does a five year old know what “feels right”? What life experience do they have to make such judgements? How can they possibly learn to read about new or abstract concepts if they must constantly refer to what they already know or feel in a given situation? How, as they grow older, do they gain new experiences with which to make these judgements, if they are only ever guessing words they already know?
Which brings us back to the operation of an LLM.
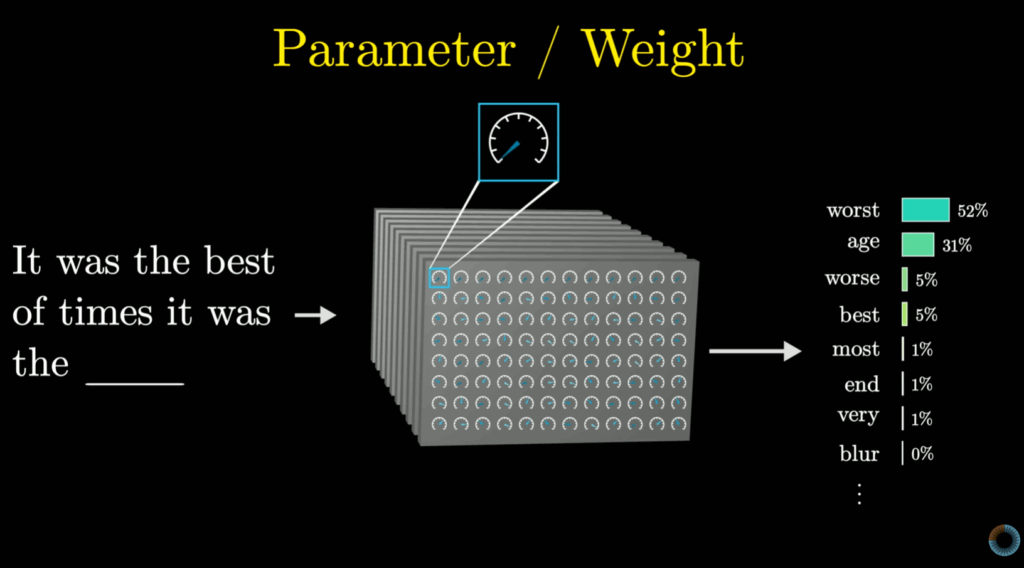
The text generated by an LLM is a probabilistic claim that this word will follow that word, in this reasonably well-defined context. Truly, they are mechanical marvels, but they are still (just) probability engines. They are not producing meaning any more than Rodney was reading. Instead, each relies on what they already know in order to create text that, according to their pre-existing models, is reasonable. The result resembles communication, but cannot convey real meaning, because it is a mathematical function that only refers to the internal model, not the world. Like Rodney’s limited life experience (bounded by the extent of childhood!), the LLM can only reference what it already knows, to create a piece of text that “feels right”, but doesn’t carry any particular intention beyond that.
In the simplistic example of the girl, her dog, and their snacks, the author cared about the girl’s relationship with her pet. The dog liked to eat with her, and she appreciated that fact about the world, so she expressed it. The author did not care to express anything about whether the dog liked the bone, but Rodney–prodded to focus on the picture of the dog by the cues–focused on that and forgot all about the little girl.
In her article, Sender quotes a conversation with the founder of the cueing system, Ken Goodman. She asked him about learning to recognise words:
“Word recognition is a preoccupation,” he said. “I don’t teach word recognition. I teach people to make sense of language. And learning the words is incidental to that.”
“The purpose is not to learn words,” he said. “The purpose is to make sense.”
For me, there is a subtle but profound difference between “making” sense and “finding” the sense that was already there. Reading, as one part of a communicative act, should remain collaborative rather than occur only within the head of the reader. Words such as those found in the children’s book above are not scattered randomly throughout the world by forces of nature–they were placed there for a particular reason, by an author, with some hope of communicating something.
That author is not the only, final, or chief arbiter of meaning–I am not advocating for some politics of domination by any stretch. Yet the opposite, the idea that the reader can “make sense” as if none were ever there before, seems to swing too far in the other direction. There remains plenty of room for a text to “make sense to me” in one way, and to you in another way–but we should both be amendable to the existence of the author as well, otherwise we create license for all kinds of texts to be interpreted to meaning anything the reader wants.
This journey through an elementary reading pedagogy sets me up to finally be able to take some kind of position on generative AI, especially text, that helps me square its sudden dominance of the social imagination. To me it has seemed incredible, inexplicable, that we would all be willing to accept what felt to me like “fake writing” in so many situations. But, with this glimpse into how younger students are being taught to read, I now have at least this tentative explanation.
If one’s method of ‘reading’ written text is to essentially deduce the meaning of a specific sentence based on external, nondiegetic cues and internal feelings, then the not only does the author not matter, the text itself doesn’t either. Authorial intention doesn’t enter into this equation, since the reader has license to insert a word (let alone interpret a meaning) that they feel is right. The sense is “made” based primarily on the reader’s decisions and judgements, and so the provenance and definition of the words themselves is actually irrelevant.
So who cares if the actual words are the output of a probability function? I’ve made them make sense, to me.